This week saw the publication of another Inc.com article by the inimitable Joel Spolsky, and as usual it's a fun, geeky read. His ranting analysis of the queueing and order taking procedures at Starbucks supplement a section about an instance of unfriendliness on the part of the staff, which I'll ignore in favour of concentrating on the (more interesting and less Godin-esque) part of the article on queueing procedures and order taking.
Read the original article [http://www.inc.com/magazine/20080801/how-hard-could-it-be-good-system-bad-system.html]; I'm only reproducing a small, relevant portion here:
"Her main job was to go down the line of people waiting to order and ask them what they wanted in advance of their arriving at the cash register. There, they would be asked to repeat their order before paying and finally joining the line of customers waiting for their drinks to appear.
This premature order taking did not appear to improve the store's productivity. The cashiers still had to take the same number of orders, wait for the customers to fiddle with their purses for the correct change, and so forth. The coffee producers -- known theatrically in the trade as baristas -- still had to make the same number of drinks. The biggest benefit of the procedure, I thought, was that the barista got started on a drink a few seconds earlier, so people got their orders filled a little bit faster, even though the overall rate of output for the store was the same.
A network engineer would say this was a situation of 'same bandwidth, lower latency' [...]"
I disagree!
Armchair Psychology
Firstly, I might have a bit of an issue with the claim of lowering perceived latency by reducing the gap between paying at the register and receiving your drink, because I believe I'd start measuring latency when first giving the order, not when paying. Let's ignore that though; Spolsky correctly assumes the early order-taking is useful in preventing customers from giving up and leaving when faced with a long line. This should be no surprise to anyone who's read Robert Cialdini's Influence: The Psychology of Persuasion [http://www.amazon.com/Influence-Psychology-Persuasion-Robert-Cialdini/dp/0688128165] Once we've expressed a choice, painted a mental picture of ourselves as buying a cup of Starbucks coffee this morning, our internal need for self-consistency will force us to rationalize staying, even in the face of long lines. Seriously, read this book, it's an eye opener.
The Benefit of Longer Queues
Ahem, sorry for the digression - back to queueing. Joel states:
"[...] while not even increasing the total number of Frappuccino Blended Coffees that could be produced per unit of time?"
Aha, that's the thing! What's missing here is that the goal isn't to increase the Frappuccino throughput, it's to increase the total throughput across all drinks, and it's absolutely crucial to realize that the drinks are different, and have different preparation times. I think the point of the pre-order taking is to increase the job queue length, and that increasing total throughput by doing this is actually an achievable goal.
Your typical Starbucks counter layout looks something like this in Canada (simplified):
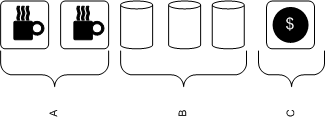
Section A: 2 Espresso machines, steam wands for frothing milk, grinders.
Section B: 3 Thermos canisters of brewed drip coffee: light, medium, dark roast.
Section C: Cash registers, in front of which customers line up.
Job Queue: {DripDarkRoast, DripDarkRoast, Cappuccino, Latte, Cappuccino}
There is no need to view the job queue as FIFO, in fact, it's intuitively obvious that reordering jobs depending on what's available at any moment (out of steamed milk - need to make more, out of ground coffee - need to grind more, etc) should improve the throughput somewhat. Now, assuming you have enough baristas, you can make 2 espresso-based drinks and 1 brewed coffee simultaneously. Maximum throughput will be achieved when all 3 execution units are kept fully busy, which means your drink pipeline should have at least two espresso drinks and one brewed coffee in it to guarantee full utilization after popping the next job off the queue, AND your staff must be allowed to reorder as they see fit. Practically speaking, since pouring a cup of drip coffee takes less time than paying for it, you should have much more than a single drip coffee job in the queue.
So the expediter can indeed cause the throughput to rise - It's clear to me that the job of the expediter is to increase the pipeline length to maximize the chance that all execution units are kept busy. One might argue that this can be done without an expediter, by having the cashiers simply take more orders and queueing them up, but that seems like it would be too much of a cognitive load: in addition to payment processing, they'd be forced to be perfectly aware of what's in the queue, who's busy, which machines are free, etc. The constant context-switching between smiling to customers, counting change, and checking the state of the queue would slow them down, which is why I think it makes sense to offload all of this decision-making to the expediter, who's then free to apply whatever algorithm she chooses in deciding whether to take more orders or pause.
The Smugness Corner
I frequently buy my morning coffee from Bridgehead Coffee in Ottawa, where the barista often sees me standing in line and starts making my usual drink before I get to the cashier to place my order, which results in incredibly low perceived latency. Go Bridgehead.

